ARM 리버스 엔지니어링 기초
유의사항
이 글은 Practical Reverse Engineering 책의 내용을 학습 목적으로 정리하고 일부를 수정하거나 추가한 내용입니다.
개요
ARM 아키텍처의 특징과 인스트럭션을 이해하고, 기초적인 리버스 엔지니어링을 연습해 보겠습니다.
ARM 아키텍처 소개
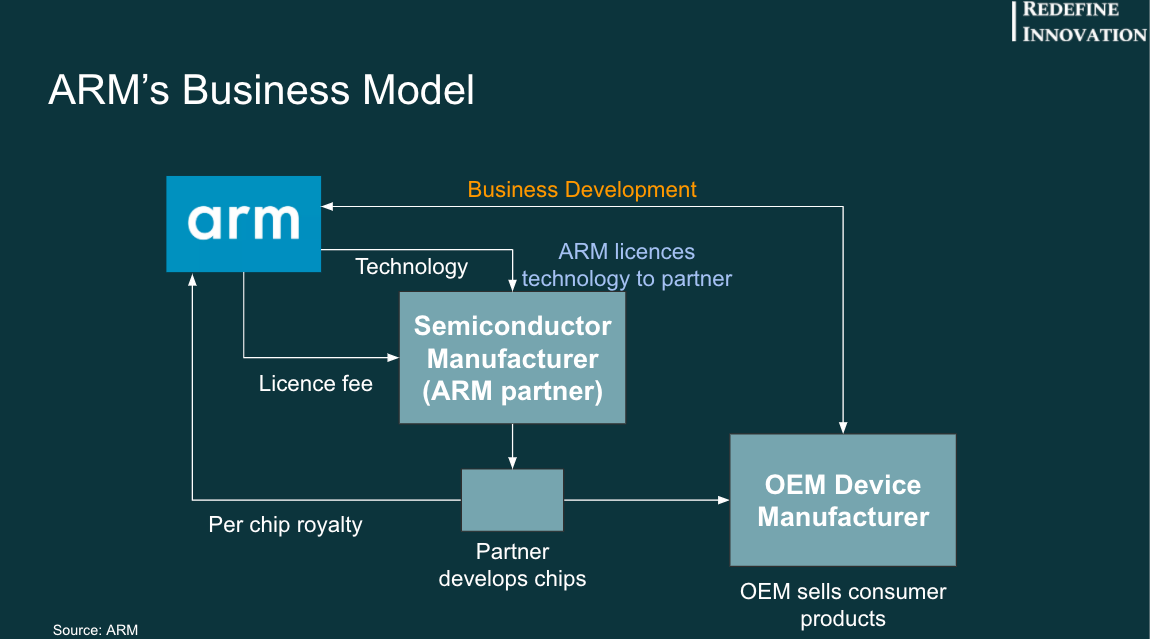
1980년대 후반 개발된 ARM 아키텍처는 휴대폰, 자동차, 텔레비전 등 다양한 임베디드 장치에서 사용되고 있습니다. ARM 아키텍처는 ARM 홀딩스가 디자인한 후 다른 회사들에 라이센스를 판매하며, 애플, 퀄컴과 같은 파트너사는 라이센스를 구매하여 자신들의 장치에 사용할 프로세서에 적용합니다. 이들 프로세서는 모두 ARM 레퍼런스 매뉴얼에 정의된 기본적인 인스트럭션 집합과 메모리 모델을 구현하고 있습니다.
ARM 아키텍처의 특징
ARM은 RISC 아키텍처로, CISC 아키텍처인 x86/x64와는 몇 가지 다른 점이 있습니다.
- ARM 인스트럭션 집합은 x86/64에 비해 작지만, 범용 레지스터의 수는 더 많습니다.
- 인스트럭션의 길이가 고정되어 있습니다.
- 메모리 접근에 load-store 모델을 사용합니다.
- 데이터를 연산하기 전 반드시 메모리에서 레지스터로 옮겨야 하며, 오직 load와 store 인스트럭션만 메모리에 접근할 수 있습니다.
ARM은 여러 가지의 서로 다른 특권 수준(privileged modes)을 제공하는데, 일단은 편의를 위해 User를 x86/64에서의 Ring 3, Supervisor를 Ring 0로 생각해도 좋습니다.
ARM 프로세서는 두 가지 상태(state), ARM과 Thumb으로 동작할 수 있습니다. 이 때 상태는 사용할 인스트럭션 집합과 관련이 있으며, 특권 수준과는 무관합니다. ARM 상태에서 인스트럭션의 길이는 항상 32비트이며, Thumb 상태에서는 16비트 또는 32비트입니다.
프로세서의 상태는 다음과 같이 결정됩니다.
BX또는BLX인스트럭션으로 분기할 때, 목적지 레지스터의 최하위 비트(LSB)가 1이면 Thumb 상태로 전환합니다.- 현재
CPSR레지스터의T비트가 1이면 Thumb 상태입니다.
대부분의 ARM과 Thumb 인스트럭션은 동일한 니모닉(mnemonic)을 갖고 있지만, Thumb 인스트럭션 중 길이가 32비트인 것은 .w 접미사가 붙습니다.
ARM은 또한 조건부 실행(conditional execution)을 지원합니다. 이는 인스트럭션에 특정한 조건이 함께 인코딩되어 있고, 이 조건을 만족하는 경우에만 실행됨을 의미합니다. 조건부 실행을 사용하면 분기문에 필요한 인스트럭션의 개수를 줄일 수 있어 유용합니다. ARM 상태에서 모든 인스트럭션은 조건부 실행이 가능하지만, 조건의 기본값은 ‘항상 실행함(AL)’ 입니다. Thumb 상태에서는 특별한 인스트럭션 IT 를 사용해야만 조건부 실행이 가능합니다.
또 다른 ARM의 독특한 기능은 배럴 시프터(barrel shifter)로, 특정한 인스트럭션은 값을 시프트하거나 회전(rotate)시키는 다른 연산을 포함할 수 있습니다. (e.g. MOV R1, R0, LSL #1 은 R0 레지스터를 왼쪽으로 1비트 시프트한 후 R1 레지스터에 대입합니다) 배럴 시프터는 조건부 실행과 마찬가지로 인스트럭션의 개수를 줄이는 데 도움이 됩니다.
범용 레지스터
ARM 아키텍처는 16개의 32비트 범용 레지스터 R0 , R1 , … , R15 를 제공합니다. 모든 범용 레지스터는 개발자가 자유롭게 사용할 수 있지만, 실제로는 앞의 12개 레지스터만 범용으로 쓰이고 나머지는 특수 레지스터처럼 사용됩니다.
R13은 스택 포인터(SP)를 나타냅니다.R14는 링크 레지스터(LR)를 나타냅니다.- 링크 레지스터(link register)는 함수의 리턴 주소를 보관하는 레지스터로, 일부 인스트럭션에 의해 사용됩니다. (e.g.
BL인스트럭션은 함수를 호출하기 전 항상LR에 리턴 주소를 저장합니다)
- 링크 레지스터(link register)는 함수의 리턴 주소를 보관하는 레지스터로, 일부 인스트럭션에 의해 사용됩니다. (e.g.
R15는 프로그램 카운터(PC)를 나타냅니다.- ARM 상태에서
PC는 x86/64와는 다르게, 현재 인스트럭션 주소에 8을 더한 값입니다. (ARM 인스트럭션 2개 뒤의 주소) - Thumb 상태에서
PC는 현재 인스트럭션 주소에 4를 더한 값입니다. (Thumb 인스트럭션 2개 뒤의 주소) PC레지스터에 주소를 대입할 수 있으며, 대입 즉시 그 주소부터 다음 인스트럭션이 실행됩니다.gdb디버거에서는PC레지스터의 값으로 현재 인스트럭션의 주소를 보여주는데, 이는 편의상PC가 alias되어있기 때문에 그런 것으로 실제와는 차이가 있음에 유의합니다.
- ARM 상태에서
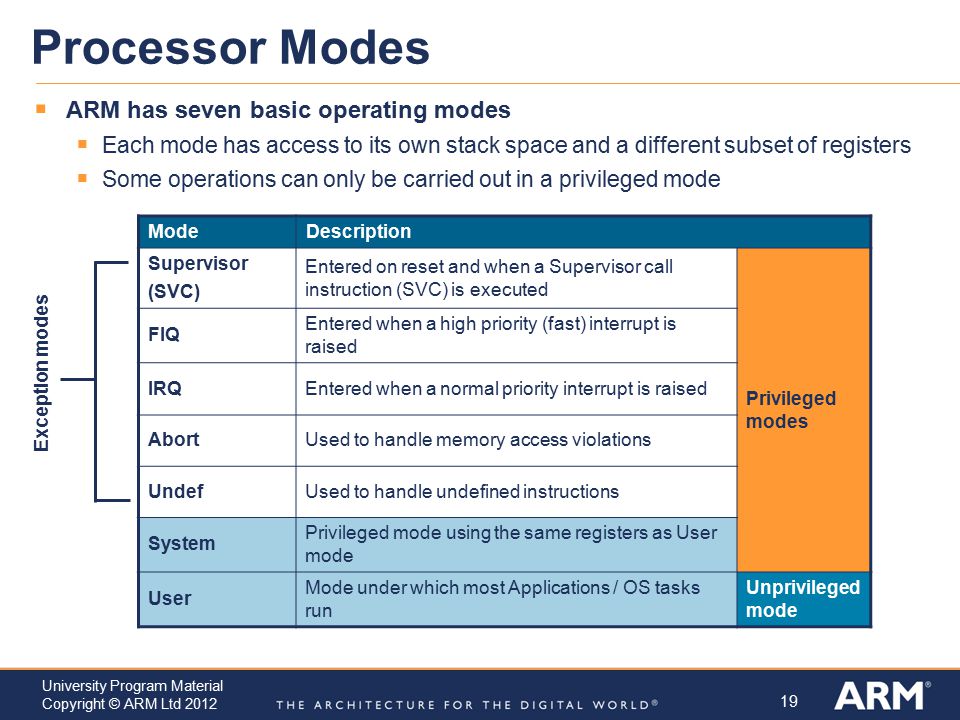
ARM은 현재 프로세서와 실행 흐름의 상태를 CPSR 레지스터에 보관합니다. (APSR 레지스터라고도 합니다) CPSR 레지스터에는 다음을 포함한 다양한 플래그들이 있습니다.
E(엔디언 비트) - ARM은 빅 엔디언 모드와 리틀 엔디언 모드 모두에서 동작할 수 있습니다.- 리틀 엔디언은 0, 빅 엔디언은 1이며 대부분의 경우 리틀 엔디언입니다.
T(Thumb 비트) - Thumb 상태인 경우 1입니다.M(Mode 필드) - 현재 특권 수준(e.g. User, Supervisor)을 의미합니다.
보조 프로세서와 시스템 설정
ARM 아키텍처는 확장 인스트럭션과 시스템 설정을 위해 사용되는 보조 프로세서(coprocessors)를 제공합니다. (e.g. x86/64에서는 시스템 설정을 CR0 , CR4 레지스터에, ARM에서는 CP15 레지스터에 보관합니다) 보조 프로세서는 CP0 , CP1 , … , CP15 의 16개가 존재합니다. (코드에서는 P0 , … , P15 로 사용됩니다) CP14 와 CP15 는 디버깅과 시스템 설정을 위해 사용되고, 나머지는 제조사가 특정한 인스트럭션을(e.g. 부동소수점 연산) 구현하기 위해 선택적으로 사용할 수 있습니다.
각각의 보조 프로세서는 16개의 레지스터와 8개의 opcode를 가지고 있으며, opcode의 시맨틱(semantic)은 프로세서마다 다릅니다. 보조 프로세서에 대한 접근은 오직 MRC , MCR 인스트럭션을 사용한 읽기와 쓰기만 가능합니다. (e.g. MRC P15, 0, R0, C2, C0, 0 은 보조 프로세서 CP15 의 C2 / C0 레지스터를 opcode 0 / 0 으로 읽어 범용 레지스터 R0 에 대입합니다) MRC 와 MCR 인스트럭션 자체는 높은 특권 수준을 요구하지 않지만, 일부 보조 프로세서의 레지스터와 opcode들은 오로지 Supervisor 수준에서만 접근이 가능합니다. 이들 레지스터를 User 수준에서 읽으려 하면 익셉션이 발생할 것입니다.
인스트럭션 집합의 특징
조건부 실행이나 배럴 시프터 외에도, ARM 인스트럭션에는 x86에 없는 특징들이 있습니다.
- 일부 인스트럭션은 레지스터의 범위를 인자로 받을 수 있습니다.
- e.g.
STM R1, {R6-R10}은 레지스터R1이 가리키는 주소에R6,R7, … ,R10의 5개 값을 순서대로 씁니다. - 연속하지 않는 레지스터들도 쉼표를 사용해서(e.g.
{R1,R5,R8}) 인자로 전달할 수 있습니다.
- e.g.
- 일부 인스트럭션은 읽기, 쓰기 이후 선택적으로 베이스 레지스터의 값을 갱신할 수 있습니다.
- e.g.
STM SP!, {R6-R10}을 실행하면SP의 값은R10의 값이 쓰인 주소의 4바이트 뒤로 갱신됩니다.
- e.g.
Load와 Store 인스트럭션
LDR 과 STR
LDR 과 STR 인스트럭션은 메모리에서 1바이트, 2바이트 또는 4바이트를 읽고 씁니다. 인스트럭션의 문법은 살짝 복잡한데, 오프셋을 지정하거나 베이스 레지스터를 갱신하는 여러 가지 방법이 존재하기 때문입니다. 가장 단순한 경우는 다음과 같습니다.
1 | LDR Rt, [Rn] ; Rt = *Rn |
LDR , STR 인스트럭션은 베이스 레지스터와 오프셋을 인자로 받는데, 오프셋의 형태가 3가지 있고 베이스 레지스터를 갱신하는 방법이 3가지 있습니다. 먼저 3가지의 오프셋 형태를 살펴보겠습니다.
- 상수가 오프셋인 경우
- 상수 값(immediate)은 단순히 정수로, 특정 오프셋의 데이터에 접근하기 위해 베이스 레지스터에 더하거나 빼는 경우입니다. (e.g. 구조체, vtable의 특정 필드 접근)
1 | LDR Rt, [Rn, imm] ; Rt = *(Rn + imm) |
- 레지스터가 오프셋인 경우
- 보통 배열에 접근하는데, 인덱스가 런타임에 계산되는 경우입니다.
1 | LDR Rt, [Rn, Rm] ; Rt = *(Rn + Rm) |
- 레지스터의 정수배가 오프셋인 경우
- 보통 반복문 안에서 배열을 순회하면서, 원소의 크기 단위로 포인터를 증가시키는 경우입니다.
1 | LDR Rt, [Rn, Rm, shift] ; Rt = *(Rn + Rm * shift) |
다음으로 베이스 레지스터를 갱신하는 3가지 방법입니다.
- 오프셋 방식
- 가장 단순하고 흔한 방식으로, 베이스 레지스터는 절대 갱신되지 않습니다.
- 느낌표(
!)가 없고 상수가 대괄호 안에 있으면 오프셋 방식입니다.
1 | LDR Rt, [Rn, offset] ; Rt = *(Rn + offset) |
- pre-indexed 방식
- 베이스 레지스터를 먼저 갱신한 후 참조합니다. (C언어의 전위 연산자와 유사)
1 | LDR Rt, [Rn, offset]! ; Rt = *(Rn + offset) |
- post-indexed 방식
- 베이스 레지스터를 먼저 참조한 후 갱신합니다. (C언어의 후위 연산자와 유사)
1 | LDR Rt, [Rn], offset] ; Rt = *Rn |
LDR 과 pseudo 인스트럭션
일부 디스어셈블 결과에서 다음과 같이 LDR 을 사용하는 방식을 볼 수도 있습니다.
1 | LDR.W R8, =0x2932E00 ; LDR R8, [PC, x] |
이 방식은 사실 pseudo 인스트럭션으로, 디스어셈블러들이 편의상 위와 같이 나타내는 것입니다. 실제로는 PC 를 베이스 레지스터로, 상수를 오프셋으로 하는 PC-relative 방식의 LDR 인스트럭션입니다.
다른 pseudo 인스트럭션으로 레이블이나 함수의 주소를 레지스터에 대입하는 ADR 인스트럭션이 있습니다. 보통 점프 테이블이나 콜백 구현에 사용되는데, 마찬가지로 내부적으로는 PC-relative 방식의 LDR 인스트럭션입니다.
1 | ADR R5, dword_9528 |
LDM 과 STM
LDM 과 STM 은 베이스 레지스터가 가리키는 주소에서 여러 개의 값을 한번에 읽고 씁니다.
1 | LDM<mode> Rn[!], {Rm} |
Rn 은 베이스 레지스터로, 값을 읽고 쓸 메모리 주소를 가리킵니다. 느낌표(!)는 선택인데, 느낌표가 있으면 베이스 레지스터를 실행 후 갱신함을(writeback) 의미합니다. Rm 은 레지스터들의 범위이며, mode 는 다음과 같이 4가지가 존재합니다.
IA(increment after) -베이스 주소부터 값을 읽고 쓰며, writeback은마지막으로 읽고 쓴 주소 + 4입니다.- 명시된
mode가 없는 경우 기본값입니다.
- 명시된
IB(increment before) -베이스 주소 + 4부터 값을 읽고 쓰며, writeback은마지막으로 읽고 쓴 주소입니다.DA(decrement after) -베이스 주소부터 낮은 방향으로(거꾸로) 값을 읽고 쓰며, writeback은마지막으로 읽고 쓴 주소 - 4입니다.DB(decrement before) -베이스 주소 - 4부터 낮은 방향으로(거꾸로) 값을 읽고 쓰며, writeback은마지막으로 읽고 쓴 주소입니다.
예를 들어, 다음은 IA 모드와 writeback을 사용하여 여러 값을 읽고 쓰는 예제입니다.
1 | LDR R6, =mem |
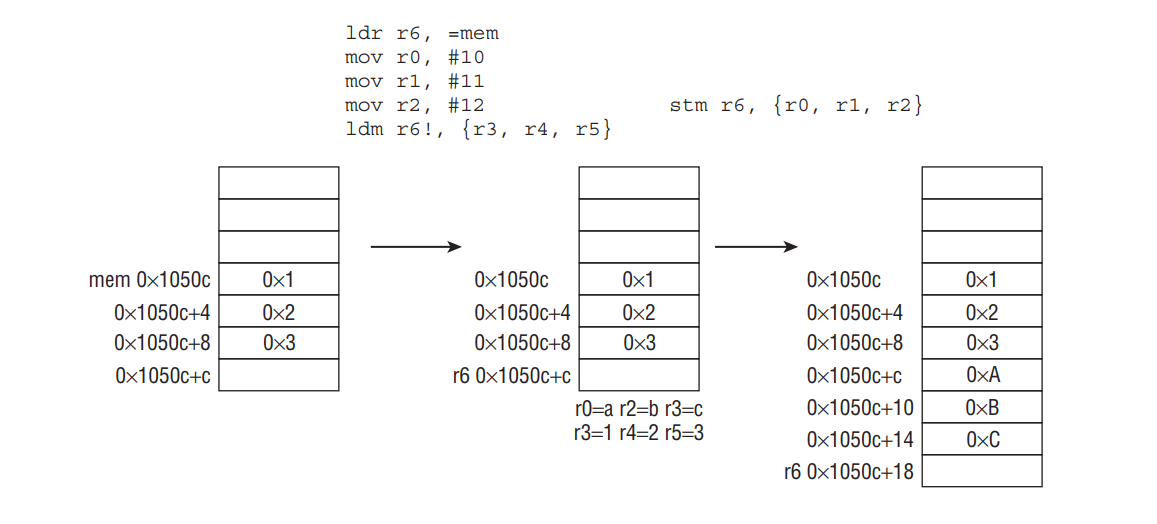
LDM 과 STM 은 한번에 여러 값을 옮길 수 있어, 보통 블록 단위의 복사 등에 사용됩니다. (e.g. 복사할 길이를 컴파일 시점에 알고 있을 경우, memcpy 대신 사용할 수 있습니다) 또한 ARM 상태에서 함수의 시작과 끝에서도 사용되는데, 함수 프롤로그와 에필로그의 역할을 합니다.
STMFD와LDMFD는 각각STMDB,LDMIA의 pseudo 인스트럭션입니다.
1 | STMFD SP!, {R4-R11,LR} ; 레지스터와 리턴 주소를 스택에 보관합니다. |
PUSH 와 POP
PUSH 와 POP 은 LDM , STM 과 비슷하지만, 두 가지 다른 특징이 있습니다.
PUSH와POP은SP를 베이스 주소로 사용합니다.- 실행 후
SP가 자동으로 갱신됩니다.
ARM 아키텍처에서도 스택은 x86/64와 마찬가지로 낮은 방향으로 자랍니다. 문법은 다음과 같으며, {Rn} 에는 레지스터들의 범위를 전달해야 합니다.
1 | PUSH {Rn} |
예를 들어, 다음은 PUSH 와 POP 을 이용해 스택에서 값을 읽고 쓰는 예제입니다.
1 | MOV.W R0, #10 |
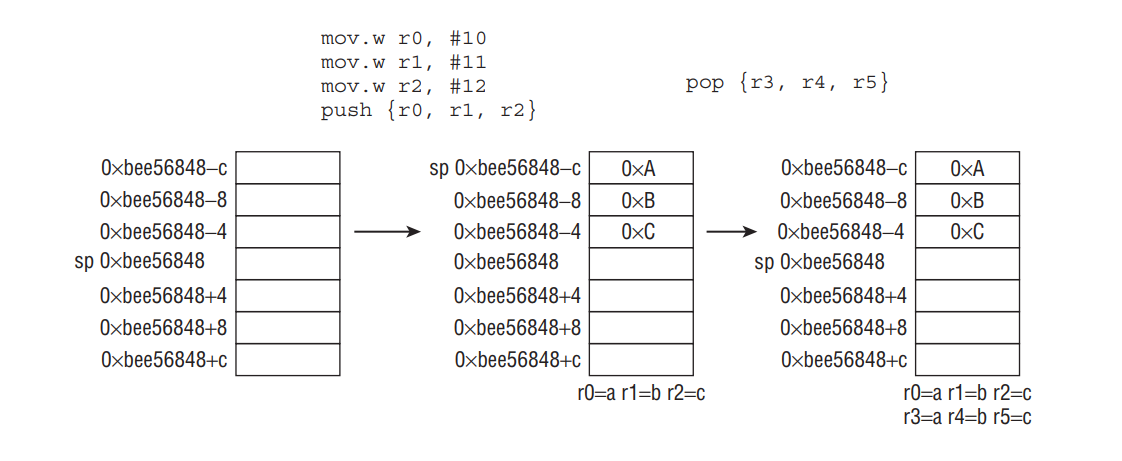
PUSH 와 POP 은 흔히 Thumb 상태에서 함수의 프롤로그와 에필로그로 사용됩니다.
1 | PUSH.W {R4-R11,LR} ; 레지스터와 리턴 주소를 스택에 보관합니다. |
함수 호출과 분기
ARM 아키텍처는 목적지 주소를 인코딩한 방식에 따라 함수 호출과 분기를 위한 다양한 인스트럭션을 제공하고 있습니다. 함수 호출의 리턴의 원리는 x86/64와 기본적으로 같지만, 몇 가지 사소한 차이점들이 있습니다.
- 리턴 주소를 스택이나 링크 레지스터(
LR)에 저장할 수 있습니다.- 함수 에필로그에서 리턴 시
POP {PC}와 같이 스랙에서 리턴 주소를 직접 꺼내PC에 대입하거나,BX LR과 같이 링크 레지스터로 분기할 수 있습니다.
- 함수 에필로그에서 리턴 시
- 분기할 때 목적지 주소의 최하위 비트(LSB)에 따라 ARM 상태와 Thumb 상태를 오갈 수 있습니다.
- 함수 호출 규약의 차이가 있습니다.
- 4개 매개변수까지 레지스터
R0,R1,R2,R3을 통해 전달하며, 나머지는 스택을 통해 전달합니다. - 리턴 값은
R0에 보관합니다.
- 4개 매개변수까지 레지스터
함수 호출과 분기에 사용되는 인스트럭션은 B , BX , BL 과 BLX 가 있습니다.
1 | B label |
B 는 단순한 분기로, x86/64에서의 JMP 와 동일합니다. 함수 호출에는 거의 사용되지 않지만, 리턴하지 않는 함수를 호출하기 위해 사용될 수 있습니다. 주로 반복문이나 조건문에서 코드 블록의 시작으로 돌아가거나 탈출하기 위해 사용됩니다. BL 은 branch with link로, 분기 전 LR 에 다음 인스트럭션의 주소를 저장합니다. x86/64에서의 CALL 과 비슷한 인스트럭션입니다. B 와 BL 은 모두 레이블의 오프셋만 인자로 받을 수 있습니다.
1 | BX Rm |
BX 는 branch and exchange로, B 와 비슷하지만 목적지 주소가 레지스터로 전달되고 ARM과 Thumb 상태를 오갈 수 있습니다. (목적지 주소의 최하위 비트가 1이면 Thumb 상태가 됩니다) 흔히 함수 에필로그에서 리턴을 위해 사용되거나, (i.e. BX LR) 다른 상태의 코드로 분기할 때 사용됩니다.
1 | BLX label |
BLX 는 branch with link and exchange로, BL 과 비슷하지만 ARM과 Thumb 상태를 전환할 수 있으며 인자로 레지스터에 보관된 목적지 주소나 레이블의 오프셋 모두를 전달할 수 있습니다. (BLX 가 레이블의 오프셋을 인자로 받는 경우는 반드시 상태를 전환하기 위함입니다) BL과 BLX 는 모두 함수 호출에 사용되는데, BL 는 현재 인스트럭션으로부터 32MB 범위 안에 있는 함수 호출에 사용하며 BLX 는 함수의 주소가 정해지지 않은 (e.g. 함수 포인터) 경우 사용합니다. Thumb 상태에서 BLX 는 주로 라이브러리 함수 호출에 사용되며, ARM 상태에서는 BL 을 대신 사용합니다.
다음 예제는 어떤 함수를 디스어셈블한 결과인데, 함수 호출과 분기를 위한 인스트럭션이 어떻게 사용되고 있는지 살펴보겠습니다.
1 | PUSH.W {R4,R5,R11,LR} |
- 1행의
PUSH.W {R4,R5,R11,LR}은 함수 프롤로그, 24행의POP.W {R4,R5,R11,PC}는 함수 에필로그에 해당합니다. - 8행에서
BLX를 이용해malloc라이브러리 함수를 호출하고 있습니다. - 20행에서
BL을 이용해foo함수를 호출하고 있습니다.
산술 연산
MOV 인스트럭션은 값을 대입하는 가장 단순한 인스트럭션입니다. 대입하는 값은 상수거나 레지스터의 값, 또는 레지스터의 값에 배럴 시프터를 사용한 값입니다. 배럴 시프터로는 값에 대한 왼쪽 시프트(LSL), 오른쪽 시프트(LSR, ASR), 회전(ROR, RRX)이 가능합니다.
1 | MOV R0, #0xa ; R0 = 0xa |
기초적인 산술 및 논리 연산 인스트럭션으로는 ADD , SUB , MUL , AND , ORR , EOR 이 있습니다. 다음 예제에서 일부 인스트럭션에는 S 접미사가 붙어 있는데, 산술 연산의 결과에 따라 CPSR 레지스터의 플래그(e.g. zero 비트, negative 비트)를 갱신해야 함을 의미합니다.
- x86/64와는 달리, ARM 산술 인스트럭션은 기본적으로
CPSR을 갱신하지 않습니다.
1 | ADD R3, R9 ; R3 = R3 + R9 |
MUL 인스트럭션은 결과의 하위 32비트만이 목적지 레지스터에 저장되며, 64비트 값 전체가 필요한 경우 SMULL , UMALL 인스트럭션을 사용해야 합니다. 또한 나눗셈 인스트럭션이 존재하지 않는데, (ARMv7-R과 ARMv7-M에 SDIV , UDIV 인스트럭션이 있기는 합니다) 실제로는 나눗셈을 소프트웨어적으로 구현하여 필요한 경우 호출하도록 합니다.
1 | MOV R1, R8 |
조건부 분기와 실행
반복문과 조건문애서 사용되는 조건부 분기는 CPSR 레지스터에서 다음과 같은 플래그들을 사용합니다.
N(negative flag) - 결과가 음수인 경우 (최상위 비트가 1인 경우) 1입니다.Z(zero flag) - 결과가 0이면 1입니다.C(carry flag) - 부호가 없는 연산의 결과 오버플로우가 발생하면 1입니다.V(overflow flag) - 부호가 있는 연산의 결과 오버플로우가 발생하면 1입니다.IT(if-then bits) - Thumb 상태의IT인스트럭션에서 조건부 분기의 조건들에 해당하는데, 뒤에서 자세히 설명합니다.
인스트럭션은 다음과 같이 조건을 나타내는 접미사 중 하나를 붙여 조건부로 실행할 수 있습니다.
- e.g.
BLT는 아래 표에서LT조건이 참인 경우에만 분기하라는 의미로, x86/64에서의JL과 같습니다.
| 접미사 | 의미 | 플래그 |
|---|---|---|
EQ |
Equal | Z == 1 |
NE |
Not equal | Z == 0 |
MI |
Minus, negative | N == 1 |
PL |
Plus, positive or zero | N == 0 |
HI |
Unsigned higher/above | C == 1 and Z == 0 |
LS |
Unsigned lower/below | C == 0 or Z == 1 |
GE |
Signed greater than or equal | N == V |
LT |
Signed less than | N != V |
GT |
Signed greater than | Z == 0 and N == V |
LE |
Signed less than or equal | Z == 1 or N != V |
비교를 위한 인스트럭션으로 CBZ , CMP , TST , CMN , TEQ 가 있으며, 비교 인스트럭션은 기본값으로 CPSR 을 갱신하지 않는 다른 인스트럭션과 달리 CPSR 의 플래그들을 자동으로 갱신합니다.
가장 흔한 비교 인스트럭션은 CMP 로, Rn 은 레지스터이고 Operand2 는 상수, 레지스터의 값 또는 레지스터의 값에 배럴 시프터를 사용한 값입니다. CMP 는 x86/64에서와 같이 Rn - Operand2 를 연산하고, CPSR 을 갱신한 후 결과를 버립니다.
1 | CMP Rn, Operand2 |
다음 여러 블록이 있는 조건문에서 조건 분기가 사용되는 예제입니다.
1 | CMP.W R3, R7, ASR #31 |
1 | if (R3 < R7) { goto loc_less; } |
다음으로 흔한 비교 인스트럭션은 TST 로, CMP 와 문법이 같습니다. 마찬가지로 x86/64의 TEST 와 같이 Rn & Operand2 를 연산하고, CPSR 을 갱신한 후 결과를 버립니다. TST 는 주로 어떤 값이 다른 값과 동일한지, 또는 특정 플래그를 검사하기 위해 사용합니다.
1 | TST Rn, Operand2 |
다음은 특정 비트를 검사하여 참인 경우 분기하는 예제입니다.
1 | LDRH R3, [R5,#0x14] |
CBZ 와 CBNZ 는 Thumb 상태에서 자주 쓰이는 비교 인스트럭션입니다. CBZ 는 레지스터 Rn 의 값이 0이면 label 로 분기하고, CBNZ 는 0이 아니면 분기합니다. 이들 인스트럭션은 주로 정수형 변수의 값이 0인지, 또는 포인터가 NULL 인지 검사하기 위해 사용합니다.
1 | CBZ Rn, label |
다음은 함수가 반환한 포인터가 NULL 인지 검사하는 예제입니다.
1 | BL foo ; 함수 foo는 포인터를 반환합니다. |
1 | a = foo(...); |
분기 인스트럭션 B 에 조건 접미사를 붙이면 (e.g. BEQ , BLE , BLT , BLS) 조건 분기를 수행합니다. 대부분의 ARM 인스트럭션에는 조건 접미사를 붙여 조건부 실행이 가능하며, 조건이 참이 아닌 경우 그 인스트럭션은 NOP 와 같이 취급합니다. 이러한 조건부 실행은 분기에 필요한 인스트럭션의 수를 줄이는 데 도움이 됩니다.
다음은 포인터가 NULL 이 아닌 경우 구조체의 특정 필드를 반환하는 예제입니다.
1 | CMP R0, #0 |
1 | if (a == NULL) { return 1; } |
Thumb 상태에서의 조건부 실행
Thumb 상태에서는 IT (if-then) 인스트럭션을 사용해야만 조건부 실행이 가능합니다. (B 는 예외입니다)
1 | ITxyz cc |
IT 인스트럭션은 뒤따르는 최대 4개의 인스트럭션까지 조건부로 실행될 수 있도록 합니다. cc 는 첫째 인스트럭션의 실행 조건이며, x , y , z 는 각각 둘째, 셋째, 넷째 인스트럭션의 조건을 나타냅니다. 이 3개의 조건은 T 또는 E 로만 나타낼 수 있습니다.
T-cc가 참이면 실행합니다.E-cc가 거짓이면 실행합니다.
다음은 if-else 블록을 IT 인스트럭션으로 작성한 예제입니다.
1 | CMP R3, #0 ; 비교 인스트럭션으로, CPSR을 갱신합니다. |
1 | if (R3 != 0) { |
Switch-case 구문
Switch-case 구문은 여러 묶음의 if-else 블록과 같습니다. 컴파일 시점에 각 case 블록의 위치를 알 수 있으므로, 컴파일러는 점프 테이블을 생성하여 switch-case 구문을 처리합니다. ARM 상태에서는 점프 테이블에 각 case 블록의 주소를, Thumb 상태에서는 블록의 오프셋을 저장합니다. 런타임에서는 점프 테이블을 읽고 목적지 주소를 PC 로 불러들이는 간접 분기(indirect branch)를 수행합니다.
다음은 ARM 상태에서 switch-case 구문의 예제입니다. ARM 상태에서 간접 분기는 PC 를 목적지 레지스터로 하는 LDR 인스트럭션을 사용합니다.
1 | CMP R1, #0xb ; R1이 case인데, 점프 테이블의 범위 안에 있는지 확인합니다. |
Thumb 상태에서는 점프 테이블에 case 블록의 주소가 아닌 오프셋을 보관합니다. 간접 분기는 특수한 인스트럭션 TBB 와 TBH 를 사용하는데, 점프 테이블의 값에 2를 곱하고 PC 에 더하여 case 블록의 주소를 얻습니다.
1 | CMP R1, #0xb ; R1이 case인데, 점프 테이블의 범위 안에 있는지 확인합니다. |
리버스 엔지니어링 연습
지금까지 살펴본 내용을 바탕으로, 예제 함수를 직접 리버스 엔지니어링해보면서 연습해 보겠습니다. 함수를 호출하는 코드는 다음과 같으며, 함수의 코드는 그래프로 나타내었습니다.
1 | LDR R3, [SP,#0x5c] |
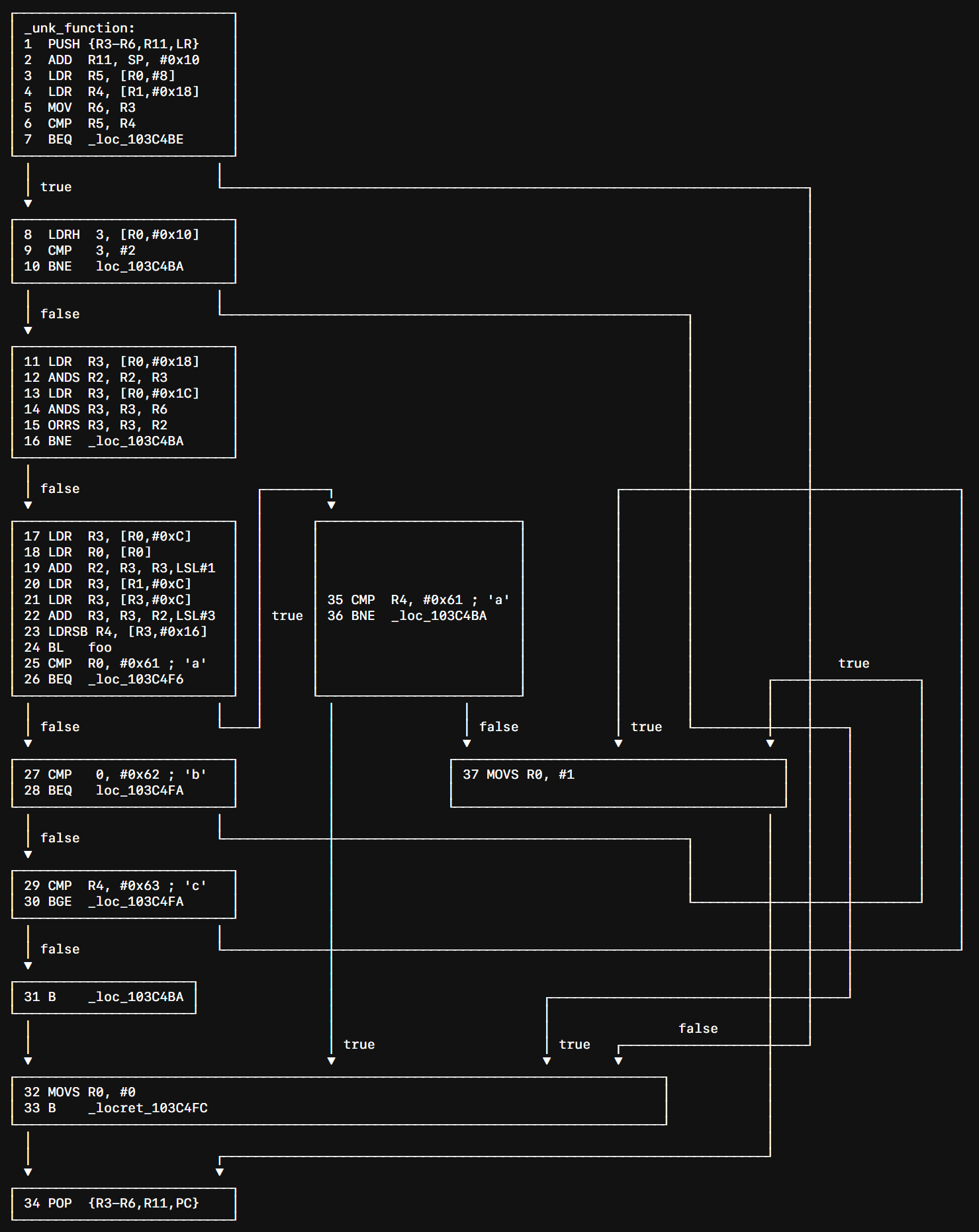
다음은 함수의 코드를 보고 빠르게 확인할 수 있는 사실들입니다.
- 함수는 최대 4개의 인자를 받고, 불리언형을 리턴합니다.
- 함수 호출 코드에서
R0,R1,R2,R3에 값을 대입하고, 함수의 리턴 직전R0에 대입되는 값은 0 아니면 1이기 때문입니다
- 함수 호출 코드에서
- 첫번째, 두번째 인자는 구조체의 포인터라고 추측할 수 있습니다.
- 3행, 4행 등에서
R0과R1이LDR인스트럭션의 베이스 주소로 사용되며, 상수 오프셋에 접근하고 있기 때문입니다.
- 3행, 4행 등에서
- 세번째, 네번째 인자의 자료형은 정수입니다.
- 14행, 15행에서
AND,ORR연산의 인자로 사용되고 있기 때문입니다.
- 14행, 15행에서
이를 바탕으로 함수의 프로토타입을 추측할 수 있습니다.
1 | BOOL unk_function(struct1 *, struct2 *, int, int) |
다음으로는 식별된 구조체들의 형태를 살펴보겠습니다.
- 3~6행에서
struct1의[R0, #8]과struct2의[R1, #0x18]을 비교하고 있습니다.- 두 필드는 동일한 타입이고, 정수형임을 추측할 수 있습니다.
- 8행에서
struct1의[R0, #0x10]을 읽고 2와 비교하는데,LDRH(load half word) 인스트럭션을 사용하고 있어short타입임을 알 수 있습니다. - 11~14행에서
struct1의[R0, #0x18].[R0, #0x1c]을 읽고 각각 세번째, 네번째 인자와AND연산을 하고 있어 필드의 타입이 정수형임을 추측할 수 있습니다.
1 | struct struct1 { |
16행까지 분석한 내용을 C 코드로 나타내면 다음과 같습니다.
1 | BOOL unk_function(struct1 *a1, struct2 *a2, int a3, int a4) { |
이후의 코드를 계속 분석해 보겠습니다.
- 17행은
struct1의[R0, #0xc]를R3에 대입하고, 18행은[R0]을R0에 대입합니다. - 19행은
R3 + (R3 << 1)을R2에 대입하는데, 이는 곧R3 * 3입니다. - 20행은
struct2의[R1, #0xc]를R3에 대입하고, 21행은 다시[R3, #0xc]를R3에 대입합니다.struct2의 오프셋0xc에 위치한 필드는 다른 구조체로의 포인터임을 추측할 수 있습니다.
- 22행은
R3 + R2 * 8을R3에 대입합니다. - 23행은
[R3, #0x16]의 바이트 값을LDRSB인스트럭션을 사용해R4에 대입합니다.
1 | struct struct1 { |
- 22행, 23행에서 레지스터 값의 정수배를 오프셋으로 사용하고 있어, 배열에 접근하고 있음을 추측할 수 있습니다.
- 배열의 베이스 주소는 20행의
[R1, #0xc]이고, 오프셋으로R3 * 3 * 8을 연산함에서 크기가 24바이트인struct4구조체들의 배열임을 알 수 있습니다.- 오프셋 계산에 사용된
R3은 인덱스로, 17행에서[R0, #0xc]를 대입한 값입니다.
- 오프셋 계산에 사용된
- 18행, 24행에서
[R0]을 인자로foo함수를 호출합니다. (foo의 인자는 1개라고 가정합니다)
나머지 코드는 foo 의 리턴값과 23행에서 대입한 R4 에 대한 단순 분기문들로, 분석한 내용을 C 코드에 추가하면 대강의 로직과 구조체 사이의 참조 관계를 파악할 수 있습니다.
1 | BOOL unk_function(struct1 *a1, struct2 *a2, int a3, int a4) { |
결론
ARM 아키텍처는 RISC 아키텍처로 인스트럭션의 길이가 고정되어 있고, 메모리 접근에 load-store 모델을 사용합니다. 특히 조건부 실행이나 배럴 시프터와 같은 독특한 기능은 적은 개수의 인스트럭션으로도 다양한 코드를 표현할 수 있다는 장점이 있습니다. 범용 레지스터나 인스트럭션의 종류 등은 x86/x64 아키텍처와 차이를 보이나, 함수 호출과 분기의 원리, 구조체의 표현 등 근본적인 부분에서는 공통점을 찾을 수 있었습니다.
참고자료
[1] B. Dang, A. Gazet and E. Bachaalany, “ARM,” in Practical Reverse Engineering. Indianapolis, IN: Wiley, 2014, pp. 39-77.